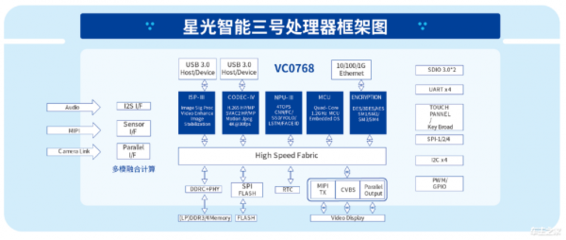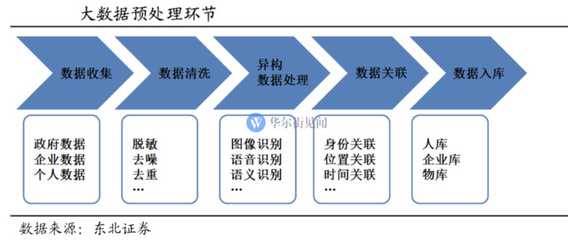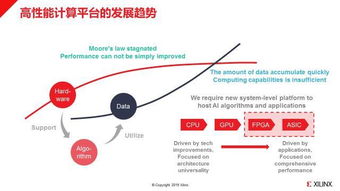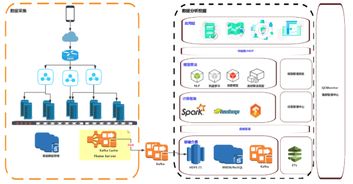
在數據驅動決策的今天,“數據工廠”作為企業數據資產生產、加工與分發的核心樞紐,其架構的先進性與健壯性直接決定了數據價值釋放的深度與廣度。我們再次聚焦“數據工廠”的架構升級,旨在探討如何構建一個面向未來、高效、彈性且智能的數據處理體系。
一、從“作坊”到“工廠”:架構演進的內在邏輯
傳統的數據處理模式往往呈現“煙囪式”或“作坊式”特點,流程割裂、技術棧繁雜、運維成本高昂。數據工廠概念的提出,正是為了將離散的數據任務標準化、流程化、自動化,實現從原始數據到業務洞察的“流水線”生產。其核心邏輯在于:
- 標準化輸入與輸出:定義清晰的數據接入規范、質量標準和交付物形態。
- 流程化與自動化:將數據清洗、轉換、集成、計算、服務化等環節串聯為可編排、可監控的工作流。
- 資源池化與彈性伸縮:計算與存儲資源解耦,根據負載動態調配,提升資源利用率和成本效益。
二、數據處理架構升級的關鍵維度
本次架構升級,需圍繞以下幾個關鍵維度展開:
1. 批流一體與實時化演進
打破批處理與流處理的技術邊界,采用統一的編程模型(如Flink)與執行引擎,實現同一套邏輯同時處理歷史數據與實時數據流。這降低了開發運維復雜度,并使得“實時洞察”與“離線分析”結果保持一致,為實時風控、實時推薦等場景奠定基礎。
2. 云原生與彈性架構
全面擁抱云原生技術棧,利用容器化(如Kubernetes)實現計算任務的敏捷部署與隔離,通過Serverless模式進一步實現細粒度資源管理和按需付費。存儲與計算分離的架構,使得兩者可以獨立擴展,從容應對數據量與計算壓力的波動。
3. 數據治理與質量內嵌
將數據治理能力(元數據、數據血緣、數據質量、數據安全)深度融入數據處理流水線。在數據加工的關鍵節點自動進行質量校驗、敏感信息脫敏,并實時記錄和可視化數據血緣,實現數據過程的可知、可控、可信。
4. 智能化運維與成本優化
引入AIops理念,利用機器學習算法對任務運行日志、資源消耗進行智能分析,實現故障預測、異常檢測、根因分析與自動修復。通過對計算資源與存儲成本的精細化監控與優化建議,實現數據工廠的“降本增效”。
5. 自助化與平民化數據開發
提供低代碼/無代碼的數據開發平臺,將復雜的技術細節封裝,讓業務分析師、數據產品經理等角色也能通過可視化拖拽的方式,參與數據管道的設計與維護,加速數據應用的交付周期。
三、面臨的挑戰與應對策略
升級之路并非坦途,主要挑戰在于:
- 歷史負擔:如何平滑遷移遺留系統與歷史任務。
- 技術復雜度:新架構引入了更多組件,對團隊技術能力提出更高要求。
- 組織協同:需要業務、數據、運維等多團隊緊密協作。
應對策略建議采用“演進式”而非“顛覆式”的路徑:
- 分域試點,價值驅動:選擇業務價值高、痛點明顯的領域(如實時報表)作為試點,快速驗證新架構收益。
- 新舊并存,逐步遷移:構建新舊兩套架構并行的雙模環境,通過數據同步與任務逐步遷移,保障業務連續性。
- 能力建設與文化轉型:加強團隊在云原生、實時計算等領域的技術培訓,并推動建立數據驅動的協作文化。
四、
數據工廠的架構升級,是一次從“技術支撐”到“價值創造”的戰略轉型。它不再是后臺默默運行的ETL任務集合,而應進化為企業核心的、智能的、可運營的“數據中樞”。通過構建批流一體、云原生、治理內嵌、智能運維的現代化數據工廠,企業能夠更敏捷地響應市場變化,更精準地驅動業務創新,最終在數據洪流中鍛造出不可替代的競爭優勢。數據處理能力的強弱,正日益成為區分行業領導者與跟隨者的關鍵標尺。